


应用场景
电力需求预测
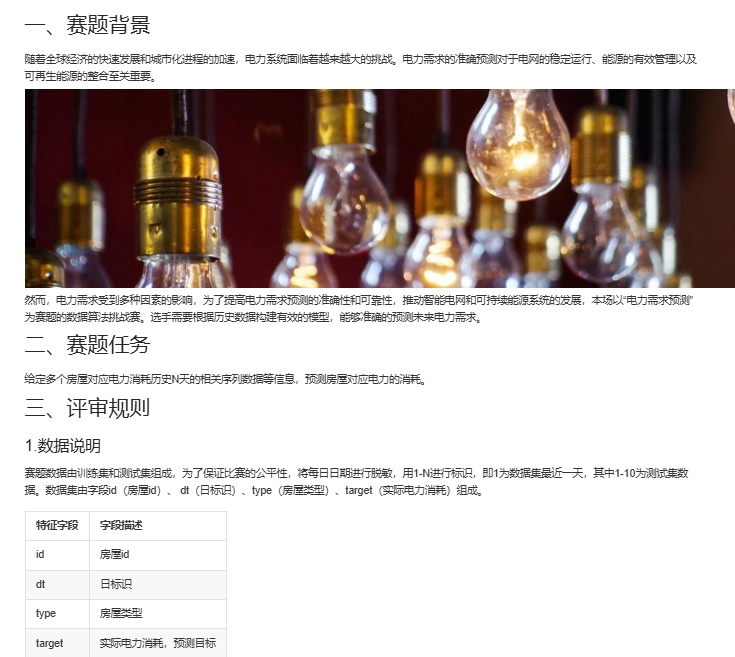
数据解析
id为房屋id,
dt为日标识,训练数据dt最小为11,不同id对应序列长度不同;
type为房屋类型,通常而言不同类型的房屋整体消耗存在比较大的差异;
target为实际电力消耗,也是我们的本次比赛的预测目标。
训练集:

测试集:
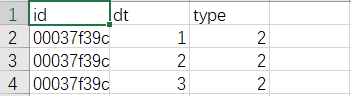
预测集示例:
基本思路
经验模型:使用均值作为结果数据
# 1. 导入需要用到的相关库
# 导入 pandas 库,用于数据处理和分析
import pandas as pd
# 导入 numpy 库,用于科学计算和多维数组操作
import numpy as np
# 2. 读取训练集和测试集
# 使用 read_csv() 函数从文件中读取训练集数据,文件名为 'train.csv'
train = pd.read_csv('train.csv')
# 使用 read_csv() 函数从文件中读取测试集数据,文件名为 'test.csv'
test = pd.read_csv('test.csv')
# 3. 计算训练数据最近11-20单位时间内对应id的目标均值
target_mean = train[train['dt']<=20].groupby(['id'])['target'].mean().reset_index()
# 4. 将target_mean作为测试集结果进行合并
test = test.merge(target_mean, on=['id'], how='left')
# 5. 保存结果文件到本地
test[['id','dt','target']].to_csv('submit.csv', index=None)这里需要解析一下计算均值的行代码。
train[train['dt']<=20]:筛选近20天的数据,注意近十天的数据是我们需要预测的train[train['dt']<=20].groupby(['id']):筛选完之后按照id进行分组,因为这里是求的均值,所以其实不太用的到房屋类型train[train['dt']<=20].groupby(['id'])['target'].mean():分组完成之后对各组target列进行求平均值train[train['dt']<=20].groupby(['id'])['target'].mean().reset_index():重置索引
这个重置索引,原理如下:
在使用groupby和聚合函数(如mean)进行分组计算后,结果通常是一个带有分组键(如id)作为索引的Series对象。这意味着分组键(id)成为Series的索引,而计算的均值成为Series的值。
即类似于如下格式:
id
1 6.0
2 3.0
Name: target, dtype: float64
使用reset_index()方法后,将索引id变成DataFrame的一列,并生成一个新的默认索引:
id target
0 1 6.0
1 2 3.0
总结来说,reset_index()将具有多级索引的Series转换为DataFrame,使得数据结构更清晰,便于后续操作。
结果
分别试了采10天和15天,看来教程里的10天更好一些:

参考资料:
从零入门机器学习竞赛 - 飞书云文档 (feishu.cn)