


1.接口设计
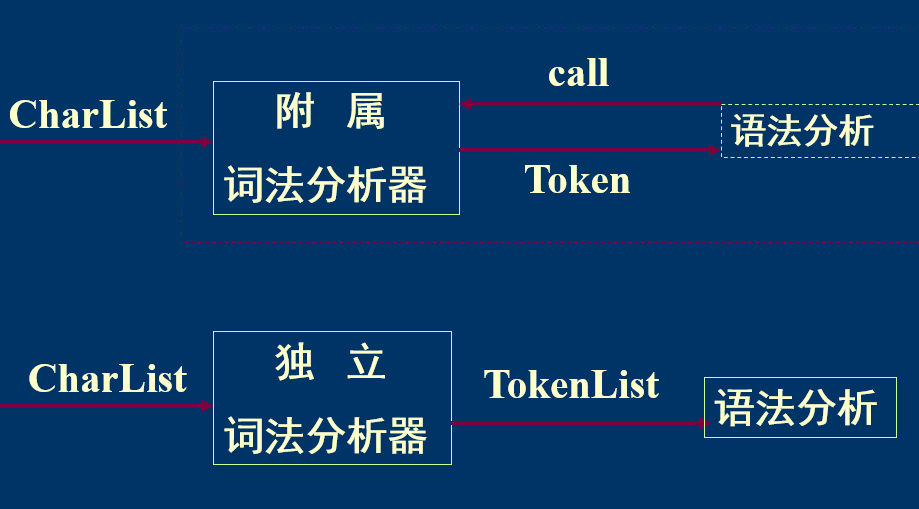
这两种方式都可以,区别在于是作为独立的板块还是被调用的板块。我是设计成独立的板块。
2.Token结构

3.词法分析器的工作过程
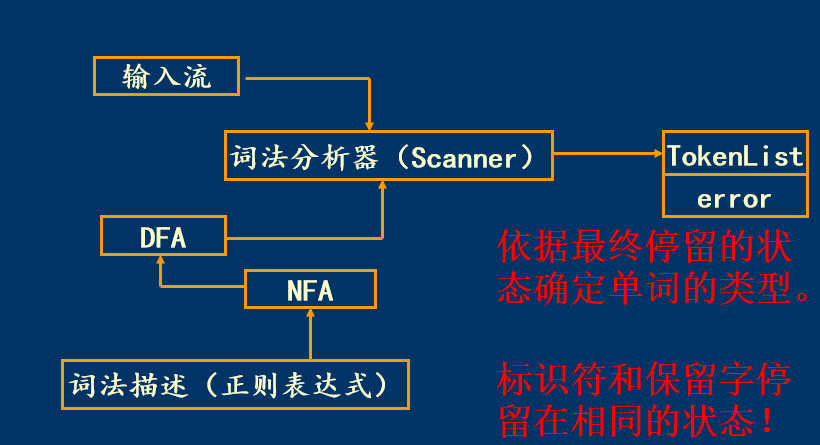
4.词法分析器的实现步骤
4.1单词的DFA描述及实现
4.2针对不同的单词生成对应的Token
4.2.1标识符的Token生成
首先查找保留字、特殊符号表,判断这个字符串是否为保留字,若是则生成保留字对应Token,不是则继续查找标识符索引表,确定其在标识符索引表中的位置,生成该标识符对应的Token。
4.2.2常量的Token生成
查找常量索引表,确定其在常量索引表中的位置,生成该常量对应的Token。
4.2.3特殊符号的Token生成
查保留字、特殊符号表,确定这个特殊符号在表中的类型编码,生成该特殊符号对应的Token。
特殊符号Token的生成过程和常量Token的生成过程比较相似,需要注意的是查保留字、特殊符号表的作用是为了确定单词的种类,这个信息填写在单词对应Token的“类别”这一项,当单词为保留字或特殊符号时,对应Token的“内容”这一项不填任何信息;而查标识符索引表和常量索引表的作用为了确定单词的内容,这个信息填写在单词对应Token的“内容”这一项,此时单词的类别已经确定了。
5.代码实现
5.1数据结构设计
Token设计:
struct Token
{
int line;
struct Word wd;
int index = -1;// tokenlist中的index
};// token
Token tokenList[1024];// token表保留字设计:
typedef enum
{
ENDFILE,
ERROR,
PROGRAM,
PROCEDURE,
TYPE,
VAR,
IF,
THEN,
ELSE,
FI,
WHILE,
DO,
ENDWH,
BEGIN,
END1,
READ,
WRITE,
ARRAY,
OF,
RECORD,
RETURN1,
INTEGER,
CHAR1, // INTEGER 是integer
ID,
INTC,
CHARC,
ASSIGN,
EQ,
LT,
PLUS,
MINUS,
TIMES,
OVER,
LPAREN,
RPAREN,
DOT,
COLON,
SEMI,
COMMA,
LMIDPAREN,
RMIDPAREN,
UNDERANGE
} LexType; // 终极符
// 保留字
static struct Word
{
string str;
LexType tok;
} reservedWords[21] =
{
{"program", PROGRAM},
{"type", TYPE},
{"var", VAR},
{"procedure", PROCEDURE},
{"begin", BEGIN},
{"end", END1},
{"array", ARRAY},
{"of", OF},
{"record", RECORD},
{"if", IF},
{"then", THEN},
{"else", ELSE},
{"fi", FI},
{"while", WHILE},
{"do", DO},
{"endwh", ENDWH},
{"read", READ},
{"write", WRITE},
{"return", RETURN1},
{"integer", INTEGER},
{"char", CHAR1}};
5.2分析函数设计
void lexicalAnalyse(FILE *fp)
{
int lineNum = 1; // line number, start from 1
// 记录行号 在后面写token的时候进行记录
int index = 0; // tokenList array index
// 用于token的记录
char ch = fgetc(fp); // f get char
// 初始化 取出第一个char
string record = ""; // 当收集到char 存入string record
// 当遇到 end of file 时暂停
while (ch != EOF)
{
// letter
// 检查是不是字母
if (isLetter(ch))
{
record = "";
record = record + ch;
////////////////取字符串开始////////////////
ch = fgetc(fp);
while (isLetter(ch) || isDigit(ch))
{
record = record + ch;
ch = fgetc(fp);
}
////////////////取字符串结束////////////////
// 字符串 有可能是ID 也有可能是reversedWord
if (isReserved(record)) // 检查是ID 还是保留字
{
// 是保留字
tokenList[index].line = lineNum; // 记录行号
tokenList[index].wd.str = getReserved(record).str; // 记录字符串
tokenList[index].wd.tok = getReserved(record).tok; // 记录token
index++;
}
else
{
// 是ID
tokenList[index].line = lineNum; // 记录行号
tokenList[index].wd.str = record; // 记录字符串
tokenList[index].wd.tok = ID; // 记录token
index++;
}
}
// int
// 检查是不是数字
else if (isDigit(ch))
{
record = ""; // 同上 用于记录
record += ch; //
////////////////取字符串开始////////////////
ch = fgetc(fp); // 把第一个取出来
while (isDigit(ch) || isLetter(ch))
{
record += ch;
ch = fgetc(fp);
}
////////////////取字符串结束////////////////
// 目前 record中已经保存有完整的字符串
int flag = 1; // all digit? 目前的版本中 只允许全部为数字的
for (int i = 0; i < record.length(); i++)
{
if (isLetter(record[i])) // 只要有字母 就退出
{
flag = 0;
tokenList[index].wd.tok = ERROR;
break;
}
}
/*
INNUM数字状态
*/
if (flag == 1) // 全部为数字 记作INTC
tokenList[index].wd.tok = INTC;
tokenList[index].line = lineNum;
tokenList[index].wd.str = record;
index++;
}
// operator
// 运算符检测
else if (isOperator(ch)) // 检查是不是运算符
{
string temp = ""; // char转string
temp = temp + ch;
if (temp == "+")
tokenList[index].wd.tok = PLUS;
else if (temp == "-")
tokenList[index].wd.tok = MINUS;
else if (temp == "*")
tokenList[index].wd.tok = TIMES;
else if (temp == "/")
tokenList[index].wd.tok = OVER;
else if (temp == "<")
tokenList[index].wd.tok = LT;
else if (temp == "=")
tokenList[index].wd.tok = EQ;
tokenList[index].line = lineNum;
tokenList[index].wd.str = temp;
index++;
ch = fgetc(fp);
}
// separater
else if (isSeparater(ch)) // 检查是不是分隔符
{
record = "";
// ignore annotation
// {}注释 忽略掉
/*
INCOMMENT注释状态
*/
if (ch == '{')
{
while (ch != '}')
{
ch = fgetc(fp);
if (ch == '\n')
lineNum += 1;
}
ch = fgetc(fp);
}
// limit operator
//
else if (ch == '.')
{
record += ch;
if ((ch = fgetc(fp)) == '.') // 记录'..'
{
/*
INRANGE数组下标界限状态
*/
record += ch;
tokenList[index].line = lineNum;
tokenList[index].wd.str = record;
tokenList[index].wd.tok = UNDERANGE;
index++;
ch = fgetc(fp);
}
else // 记录'.'
{
tokenList[index].line = lineNum;
tokenList[index].wd.str = record;
tokenList[index].wd.tok = DOT;
index++;
}
}
// string
/*
INCHAR字符标志状态
*/
else if (ch == '\'')
{
tokenList[index].line = lineNum;
string temp = "";
temp = temp + ch;
tokenList[index].wd.tok = CHARC;
while ((ch = fgetc(fp)) != '\'')
{
record += ch;
}
tokenList[index].wd.str = record;
index++;
ch = fgetc(fp);
}
// :
else if (ch == ':')
{
record += ch;
if ((ch = fgetc(fp)) == '=')
{
/*
INASSIGN赋值状态
*/
record += ch;
tokenList[index].line = lineNum;
tokenList[index].wd.str = record;
tokenList[index].wd.tok = ASSIGN;
index++;
ch = fgetc(fp);
}
else
{
tokenList[index].line = lineNum;
tokenList[index].wd.str = record;
tokenList[index].wd.tok = COLON;
index++;
}
}
//
else
{
tokenList[index].line = lineNum;
string temp = "";
temp = temp + ch;
tokenList[index].wd.str = temp;
if (temp == "(")
tokenList[index].wd.tok = LPAREN;
else if (temp == ")")
tokenList[index].wd.tok = RPAREN;
else if (temp == "[")
tokenList[index].wd.tok = LMIDPAREN;
else if (temp == "]")
tokenList[index].wd.tok = RMIDPAREN;
else if (temp == ";")
tokenList[index].wd.tok = SEMI;
else if (temp == ",")
tokenList[index].wd.tok = COMMA;
index++;
ch = fgetc(fp);
}
}
// blank
// 检查是不是 blank
// 空格 制表符 回车 换行
else if (isBlank(ch))
{
if (ch == '\n') // 换行符特殊处理 行号+1
lineNum += 1;
else
;
ch = fgetc(fp);
}
// unknown
else
{
string t = "Line ";
t += to_string(lineNum);
t += " ";
t += "\"";
t += ch;
t += "\" ";
t += "UnknownToken Error!\n";
printErrorMsg(t);
}
}
/*
DONE完成状态
*/
tokenList[index].line = lineNum;
tokenList[index].wd.str = ch;
tokenList[index].wd.tok = ENDFILE;
}参考资料:
GitHub - Yichuan0712/SNL-Compiler: SNL 编译器 词法分析 语法分析 语义分析
吉林大学编译原理PPT(刘宇舟)