


Stable Video Diffusion本地部署
在线体验
stability-ai/stable-video-diffusion – Run with an API on Replicate
Stable Video Diffusion - a Hugging Face Space by multimodalart
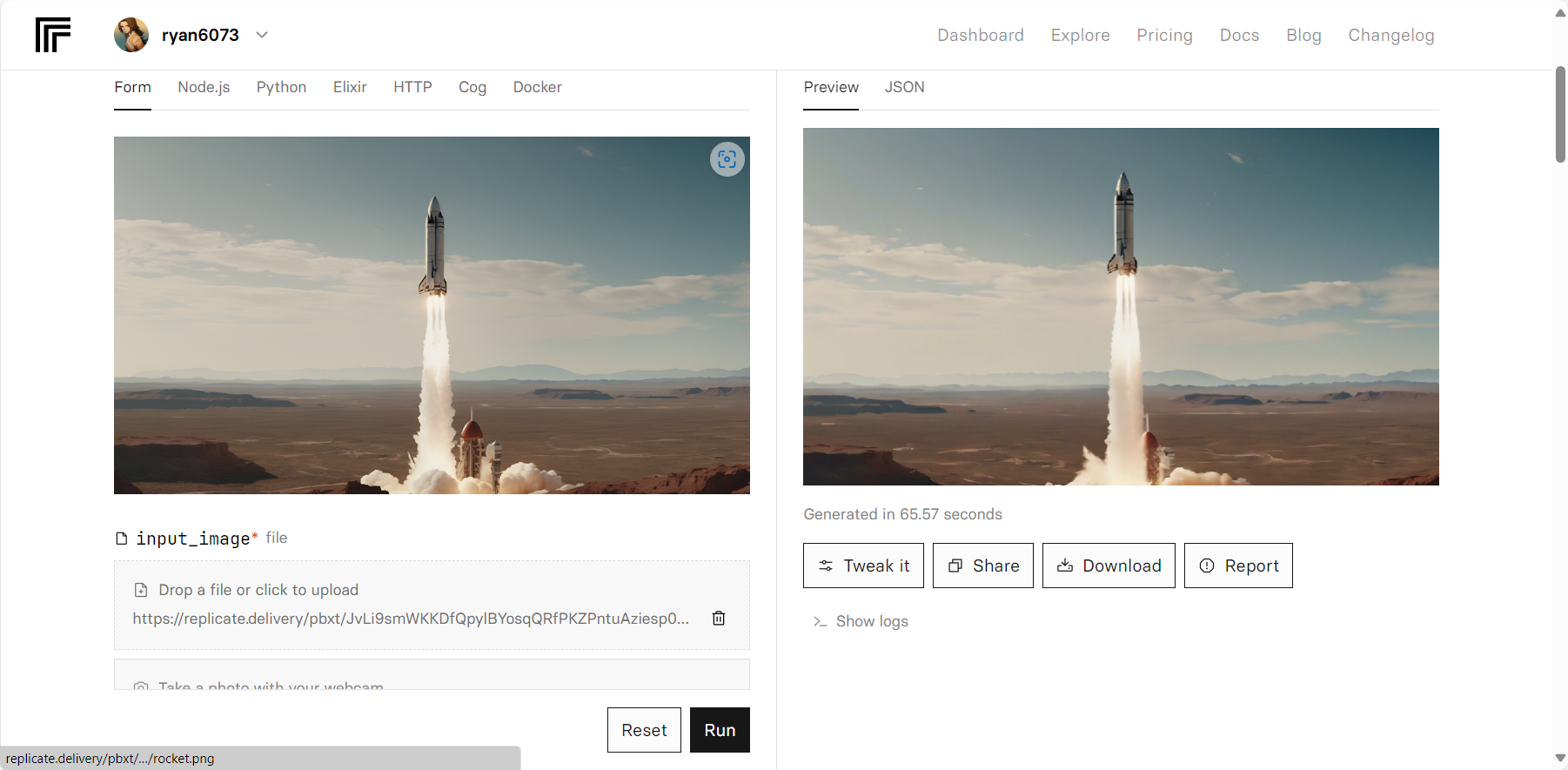
调用方式一:web API调用
stability-ai/stable-video-diffusion – API reference (replicate.com)
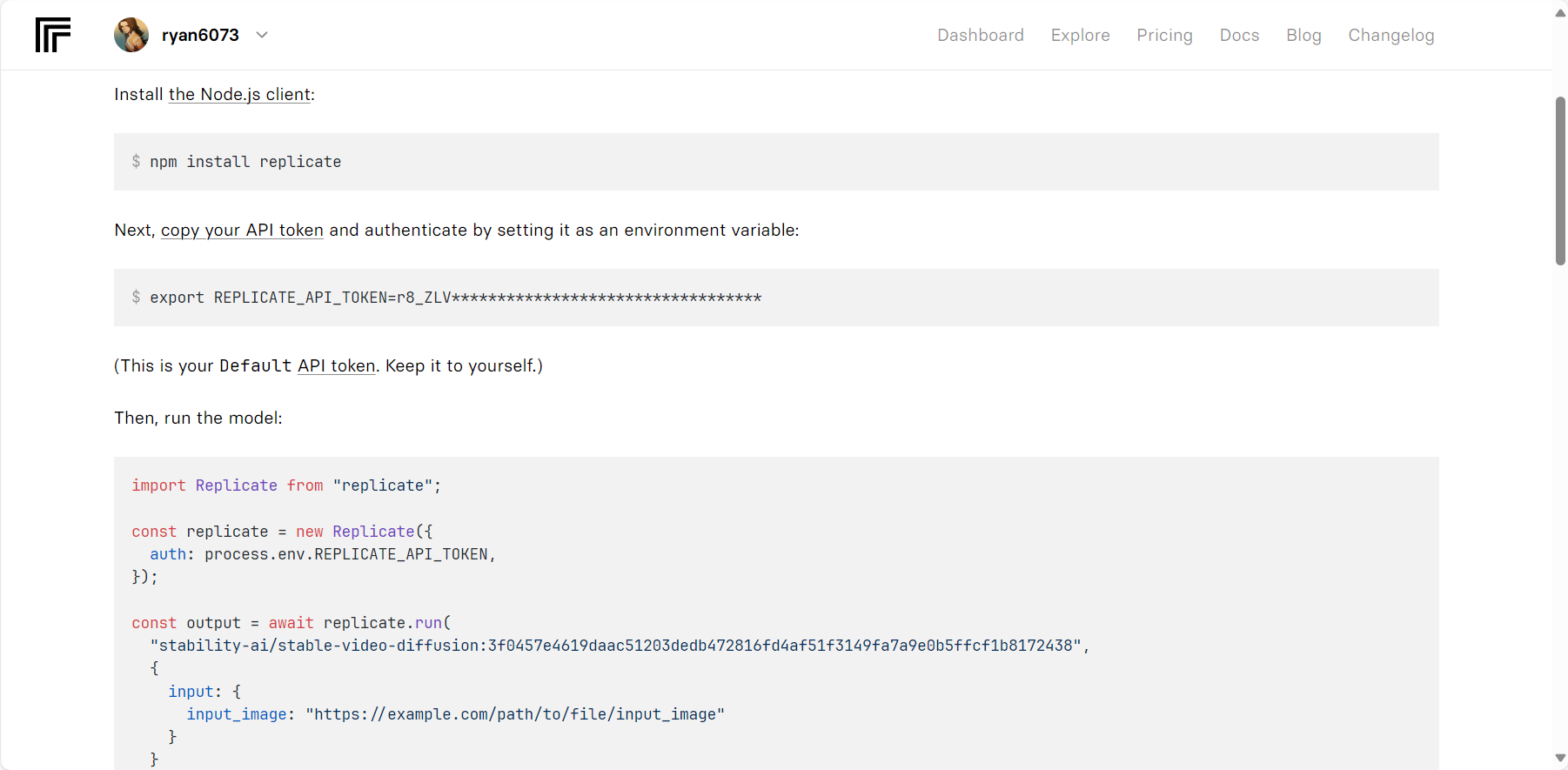
需要购买API额度,可以轻松调用
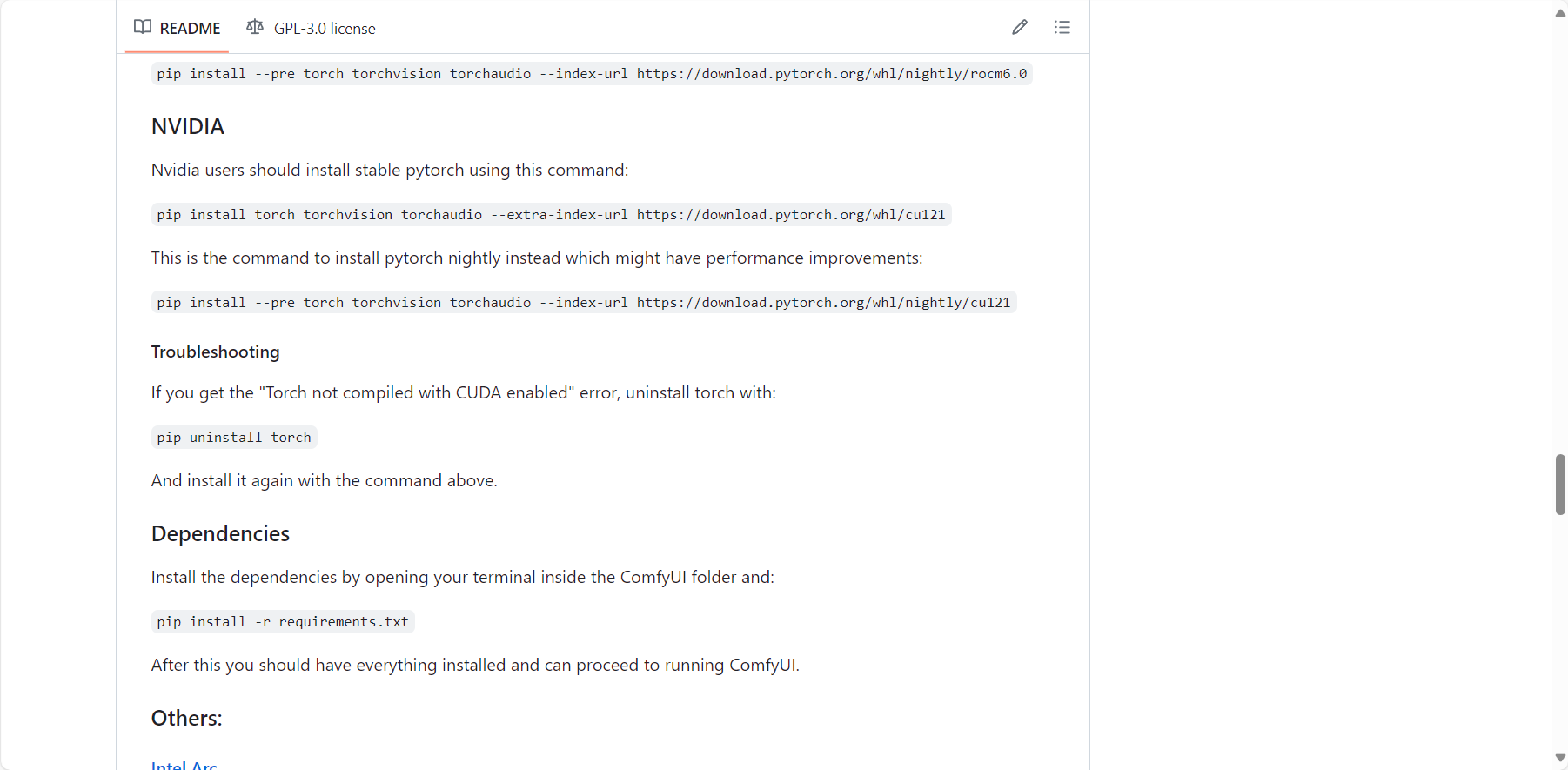
调用方式二:模型本地部署调用计算(Windows)
1. safetensors模型下载
stabilityai/stable-video-diffusion-img2vid at main (huggingface.co)
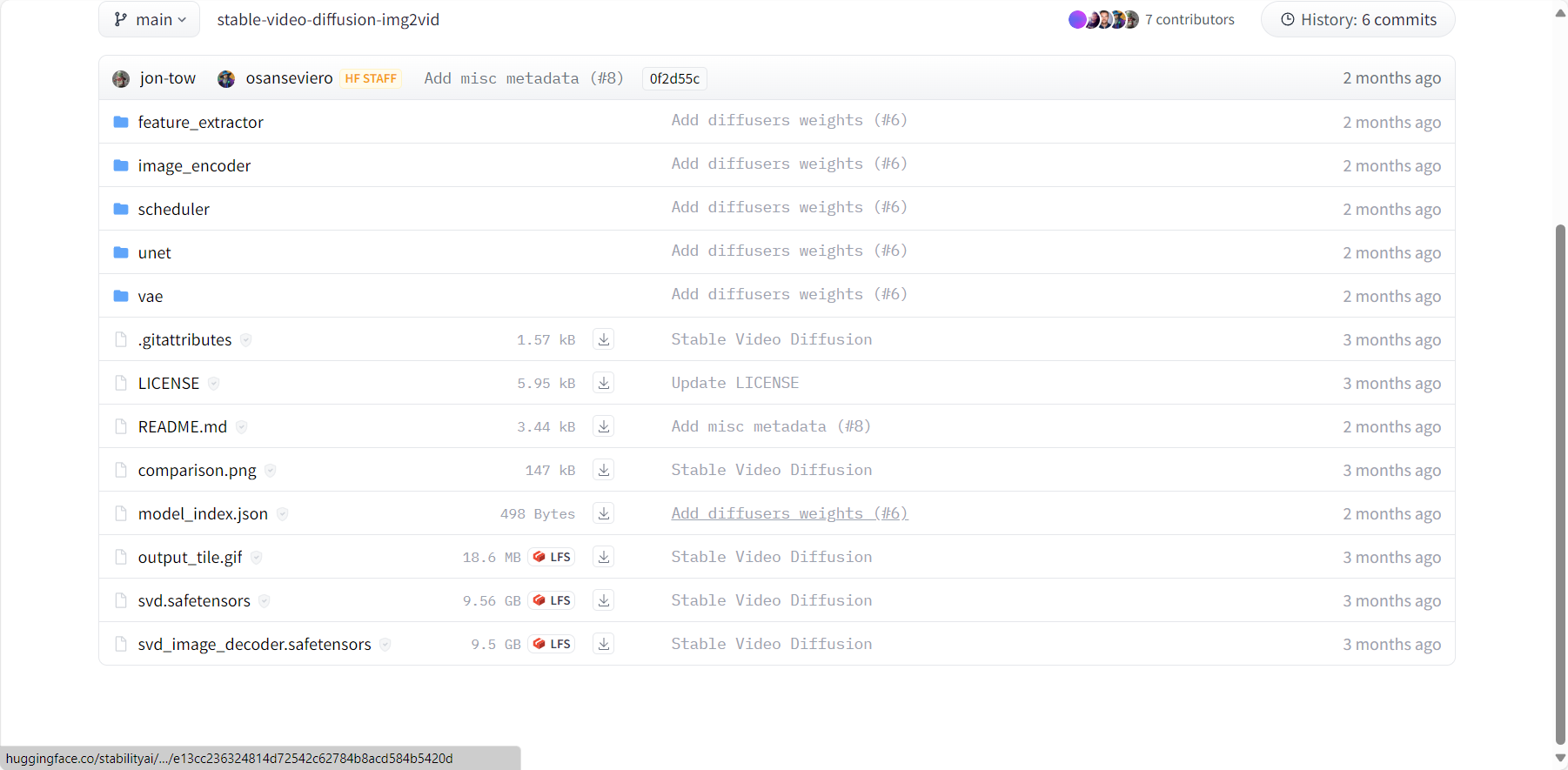
下载svd.safetensors或者svd_image_decoder.safetensors模型,这两个模型的区别是一个是生成14帧的视频,一个是生成25帧的视频,也可以两个都下载
2. ComfyUI客户端下载
Releases · comfyanonymous/ComfyUI (github.com)
环境配置:Releases · comfyanonymous/ComfyUI (github.com)
安装教程:【ComfyUI】安装 之 window版_comfyui下载-CSDN博客
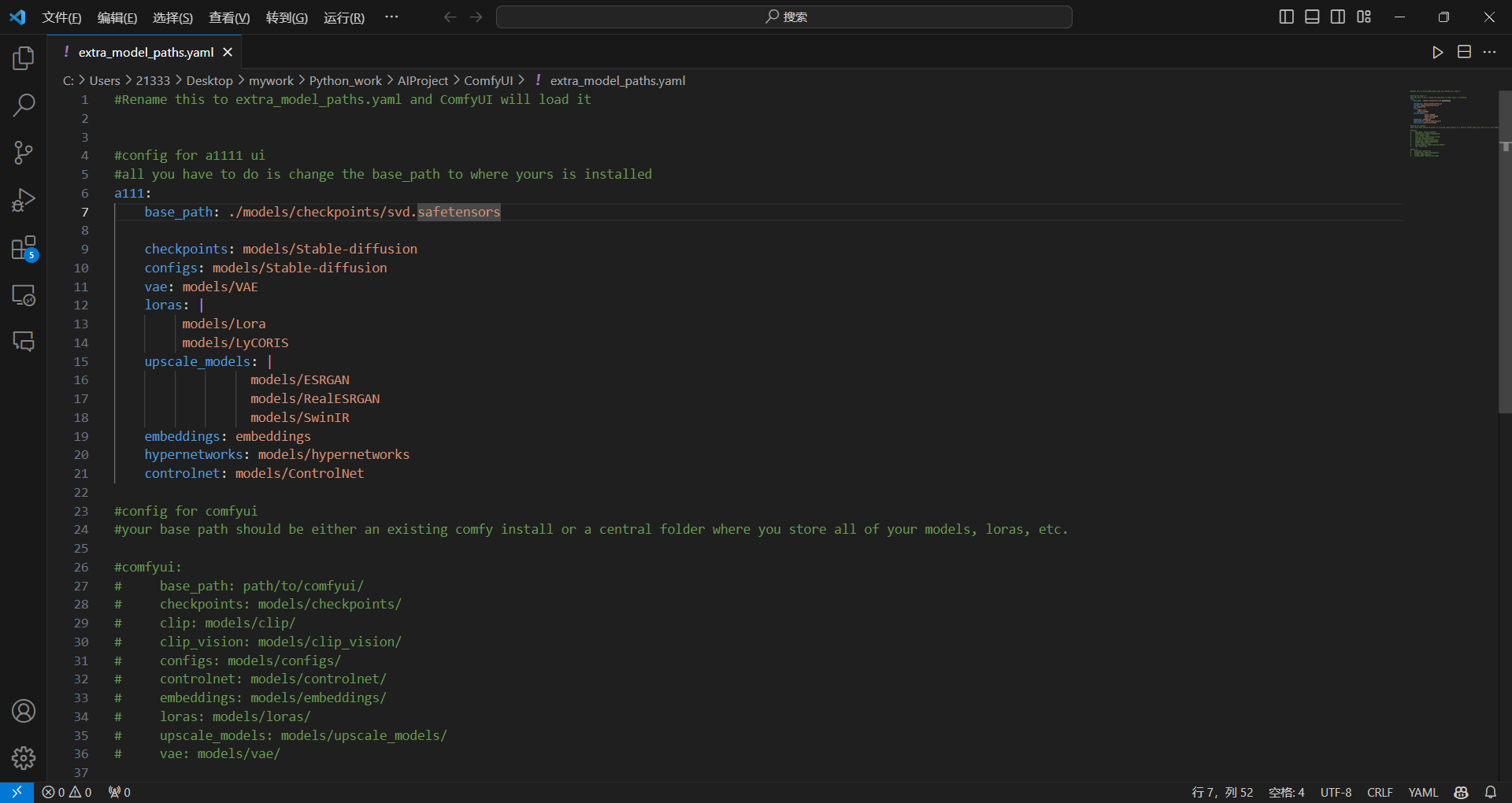
注意这里的svd模型也是直接放到models/checkpoint里就行。yaml文件修改如下:
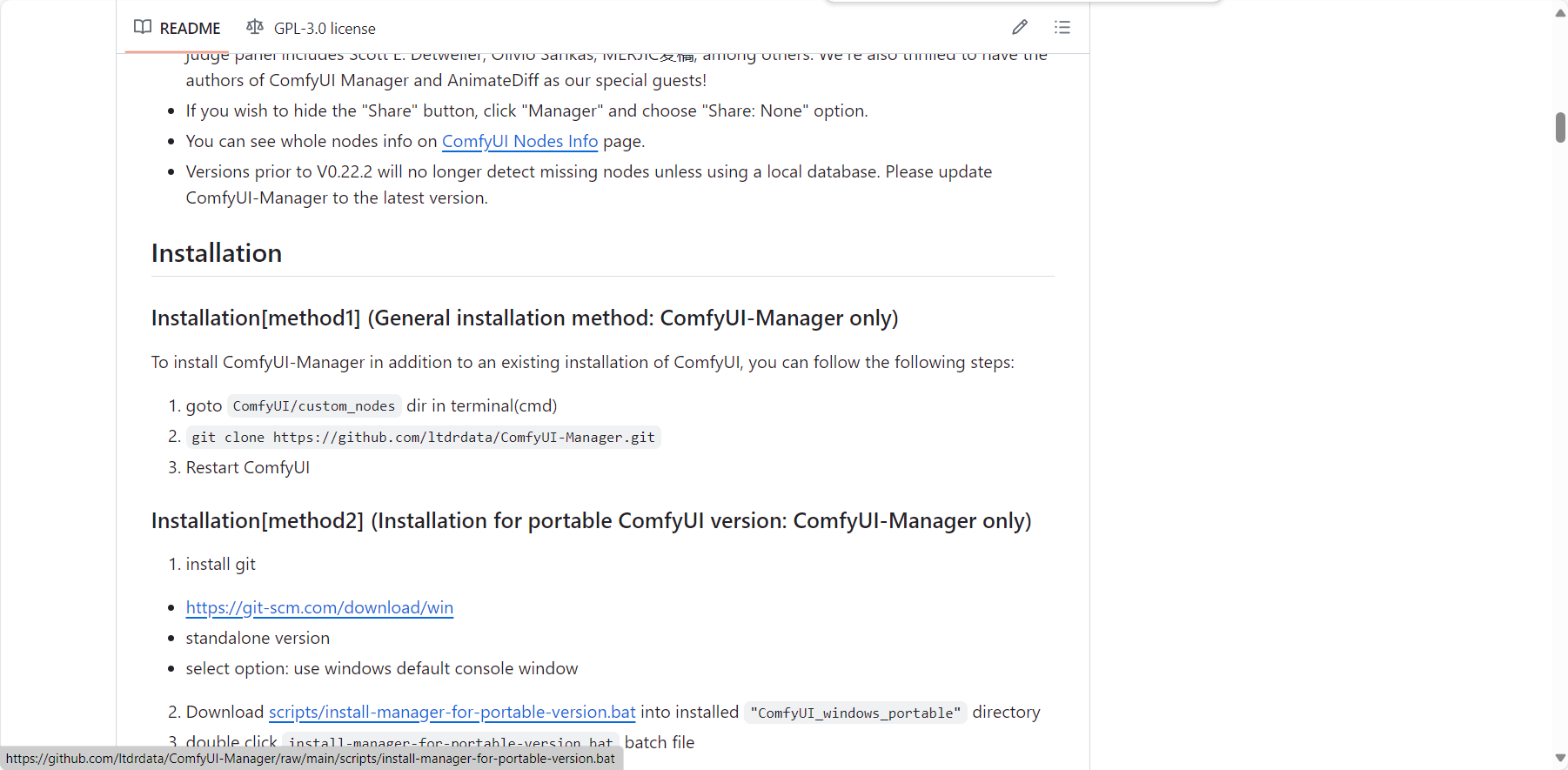
3. ComfyUI Manager下载
这个是i2v需要的工具,而且可以在前端更新ComfyUI,同时ComfyUI必须是最新版本才能使用,所以这个拓展工具是必须的。
ltdrdata/ComfyUI-Manager (github.com)
在对应目录下打开命令行,之后按照readme文档进行操作即可:
4. 导入SVD配置文件并加载,安装缺失配置文件
本地部署,Stable Video Diffusion AI视频开源发布,ComfyUI工作流|AI视频|最新SD Video模型 - YouTube
从4:05开始SA
5. 使用技巧
Stable Diffusion ComfyUI 入门感受 - 知乎 (zhihu.com)
调用方式三:模型本地部署调用计算(Linux)
# CUDA 11.6
conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.6 -c pytorch -c nvidia
python==3.9
部署好了之后,考虑下面几个点:
选择效果最好的safetensors模型
这一步,需要找到模型和对应的workflow工作流文件
打通自动化流程
需要先把程序都转移到Linux上,然后写脚本把所有程序串起来
样例学长已经发了,使用吉米的故事作为样例进行自动化测试
在图生视频这里,格式是可以固定下来输出到特定的文件夹的,目前最大的问题是怎么把参数传入SVD的main.py 文件中
如果你要改默认工作流,那就要直接把SVD 的工作流复制进这个文件。 ComfyUI/web/scripts/defauiltGraph.js
搞清楚自动化各部分之间的信息传输形式
以json的格式传输,格式还没确定,方式还没确定
问题需要解决:
-
生成一段程序之后 [rgthree] Using rgthree's optimized recursive execution. Prompt executed in 0.01 seconds got prompt [rgthree] Using rgthree's optimized recursive execution. Prompt executed in 0.01 seconds